- Home >
- Browse this journal/Dans cette revue >
- 10/2018 Le web 2.0 : lieux de perception des trans... >
- Le web 2.0 : lieux de perception des transformatio... >
A statistical analysis of French teachers’ blogs: beyond institutional perspectives
Some changes in the teaching profession made visible by the study of their blogs
Résumé
Notre recherche de nouvelles sources d'analyse nous a conduits à construire une méthode quantitative inductive, basée sur l'analyse de champs lexicaux (topic model) pour étudier les blogs des enseignants. Cette approche permet d'acquérir de nouvelles connaissances sur les préoccupations des enseignants dans des domaines attendus, tels que leur discipline ou leur usage de la technologie numérique, mais aussi dans des domaines inattendus, tels que les questions de code vestimentaire ou les attentats terroristes. L'article présente la méthode, comment et pourquoi celle-ci nous offre de nouvelles opportunités pour l'analyse d'un type relativement nouveau de source écrite, les blogs.
Abstract
Our search for new sources of analysis has led us to build a quantitative inductive method based on the analysis of lexical fields (topic models) to study teachers’ blogs. This approach generates new insights about teachers’ concerns in expected areas, such as their discipline or their own use of digital technology, but also in unexpected areas, such as dress code issues, or terrorist attacks. This article presents our method, and explains how and why it provides us with new opportunities for the analysis of a relatively new type of written source, namely blogs.
Table of content
Full text
Introduction
1The reason why we decided to study teachers’ blogs originally came from the fact that 'digital use' is understood and used by teachers as meaning an "institutional use" of digital technology: any institutional use of digital technology is perceived as innovative, while teachers who use digital technologies in a non-institutional framework are not necessary aware of it.
2As a result, teachers' answers to qualitative or quantitative surveys conducted by researchers mainly reflect those teachers' understanding of the institutional demand for digital use. Initial ethnographic research based on interviews and observations (Epstein 2016) and "traditional" quantitative research in the form of a questionnaire (Epstein Bouccara 2015) show that the use of digital technology among teachers is unconscious. Thus, non-directive interviews (Matalon & Ghiglione 1998) have major shortcomings, since interviewed teachers do not mention digital use (Ladage & Ravenstein 2013) and semi-directive interviews lead to agreed-upon answers. Finally, non-participating observations are richer but necessarily relate to a limited corpus. We were seeking a way to expand beyond non-participating observations or non-directive interviews.
3Blogs are a form of self-staging (Rouquette 2008, Goffman 1973) which has been studied in marketing more than in sociology. Nevertheless, blogs are used by different professionals in order to get a reflective feedback on their profession (Mortensen & Walker 2002 for researchers, Dardy 2016 on the study of bloggers aspiring to be writers, Henaff 2009 for a teacher) or to deal with taboo issues (Lang 2016 on female sexuality). The data produced by such studies can be analyzed sociologically, provided that the conditions in which they are generated are controlled for and, in the first place, the motivations and aims of the blogger himself are known (Jones & Alony 2008).
4Cardon and Delaunay (2006) suggested four categories in their typology of blogs: "anonymous sharing of privacy, casual conversation between close relatives, community coordination and public exchange of views". In the blogs which we studied, we observe different forms of community coordination (between teachers of the same discipline, between teachers and their students, between teachers of the same school), anonymous sharing of professional questions, and public exchange of views on education.
5We therefore wish to benefit from both the richness of the long written sources (which allows for inductive research) and the massive nature of the data, thanks to the use of appropriate quantitative tools on a vast corpus that is not constrained by a survey. These sources provide massive data, so we propose a method of analysis based on a lexicometry tool, namely the topic model methodology. We use computing tools and quantitative analysis to conduct qualitative sociological exploration work, within limits that we will explain. We will thus show that this inductive method allows the emergence of new perspectives regarding middle and high school teachers in France and that we do not need any representative sample in order to do that.
6The first part of the work is gathering data. The basic tool consists of a set of Python scripts created for the study that collects the html source files of the blogs and removes technical or design elements in order to obtain articles in text format and build our reference database.
7The second part consists of statistical processing operations, along with their intermediate modeling processes. After extensive cleaning of the dataset, we start with lexicometry through topic models [Blei 2003, Bourgeois and Lavenir 2016]. The topic model technique is a probabilistic analysis technique based on the idea that observed sources (here, blogs) can be modeled as the result of a random generative process using pre-existing elements (mainly lexical fields). Our objective is to find those constitutive elements, and analyze the results with simple quantitative tools including Principal Component Analysis.
8After presenting the corpus and detailing the quantitative methods we used, we will present the results and show that the analysis of blogs and categories built on topic model enables a better understanding of changes in the teaching world and is a promising method for studying professional changes.
The Corpus
9A first technical and methodological difficulty lies in the choice of observations. As mentioned in the introduction, we have favored blogs over more frequently studied formats such as Twitter entries. We believe that the diversity of formats and the absence of editorial constraints (especially on the number of characters, but also on the design of the page itself for example) give authors a degree of freedom in expressing themselves that is closer to the format of the non-directive interview we have in mind. Moreover, a single blog can contain hundreds of articles, each of which may contain a large amount of text. The quantity of available text makes some lexicometric analysis techniques more effective than on shorter formats. On the other hand, the blog format will yield far fewer different authors for a corpus of identical size (from 7 articles to over 7000 articles in a blog). In any case, the specific technical difficulties in collecting such a diverse corpus – we will expand on this point later on – would not allow us to carry out the same study on thousands of blogs.
10We adopted a two-step approach to build our corpus. As a first step, given that it is impossible to study Francophone blogs exhaustively, we arbitrarily chose a blog database for our study. We searched for "prof blog" on Google and gathered a few dozen blogs (advertising blogs, redundant links, etc. were discarded). In a second step, we added to our corpus those blogs referenced by the blogs already selected above. The resulting set is not meant to be a representative sample, a notion that in itself makes no sense for such an open set. This mixed selection is due to the fact that we try to balance two different selection biases, neither of which can be entirely avoided. On the one hand, Google’s search algorithm (PageRank) specifications are not public, and selecting popular blogs according to this algorithm certainly implies a bias. On the other hand, we assume that blogs are partially structured in communities; so selecting blogs that refer to each other, while bypassing this popularity problem, might give extra weight to these communities.
11Finally, our study focuses on a set of 39,982 articles distributed over 47 blogs of which they form the integral content. The choice of blogs was made semi-arbitrarily based on their visibility on the Google search engine among those with common characteristics:
-
they are written by secondary school teachers in the French school system (public or private),
-
they are predominantly French-speaking (even though blogs by teachers of modern languages often have sections in the language taught and even though English words are ubiquitous)
-
they are still active in 2017, regardless of their starting date.
12We asked teacher-bloggers among those for permission to quote them, authorizations that they gave us and for which we wish to thank them.
General Characteristics
13Qualitative data were manually extracted from the blogs using either the "A propos" (About) section when it existed, or links to Twitter, Facebook or LinkedIn, or the commenters (sometimes students, sometimes colleagues) who knew the teacher and to whom they replied. The use of pronouns when the blog was anonymous also made it mostly possible to determine the author's gender1.
14The following socio-demographic information was collected as a result of this analysis: gender (2 answers missing), discipline taught (no missing data), region (35 answers found, 12 missing), rural or urban situation of the school (35 answers found, 12 missing), seniority (32 answers found, 4 missing and 10 uncertain answers constructed from phrasing such as "during my year of IUFM2" or other information giving contextual elements), and type of school (middle school, high school, professional high school, etc.).
15This first qualitative analysis also reveals whether blogs are intended for students, colleagues, or a general audience. It makes it possible to distinguish blogs that are more likely to be "resource blogs" for colleagues or students with elements for learning, from usually anonymous "professional diaries", which are more often thought-provoking blogs on professional practices, or militant or political blogs which try to demonstrate an interest or lack of interest in any particular reform. Some blogs are both resource and activist blogs and the categories are not exclusive. Some blogs are, conversely, mostly more intimate blogs about life "in general" or about a passion "in particular" with some rare references to the profession.
Dominance of history-geography and French teachers
16Although we did not make any a priori selection according to this criterion, almost all blogs are written by teachers from the public school system; the only exception being a philosophy teacher from a private secondary school in Île-de-France. We can also notice that the number of middle school teachers is twice as large as the number of high school teachers among those for whom it was possible to obtain this information (28 vs. 14).
17As we noticed, and this may even be considered as a first insight, some disciplines (French and History) are easier to find than others on Google and are more represented in our sample than others. Nevertheless, there is a great diversity of fields in our sample: history and geography (10), French as a foreign language (1), other foreign languages (3), mathematics (6), sports (2), documentation (4), technology (3), management (1), philosophy (1), biology and geology (1), economics and social sciences (1) etc.... The most represented one is French with 10 blogs and one about literature and history (in a vocational high school), and the most notable absentee is physics-chemistry even though there is a blog from a mathematics and sciences teacher in the sample.
18Similarly, teachers are spread throughout the country, with all 10 French administrative Regions represented. Finally, the gender distribution shows a clear over-representation of men (27 men and 18 women plus two unidentified). This is a strong bias since women are over-represented in the public school system (58% of women in public secondary education according to DEPP3's RERS 2017).
19Blogs vary greatly in terms of length. The lengthiest one features 7319 articles, while the smallest contains only 7. The articles themselves vary greatly in size, with some authors writing essays where others prefer short posts, sometimes a single sentence as a commentary on an image or video.
20This information is important for the analysis (this is not a representative sample of teachers in France) but does not invalidate our results, which aim at understanding what teachers are concerned about apart from issues about their discipline.
21Acquisition and selection of information
22The study of blogging articles poses a new problem compared to a traditional study of articles from the press: it is more difficult to decide what the actual content of a blog post is. While the newspaper article is usually a homogeneous block with a simple cap containing a title, date and sometimes author, a web page is full of data whose relevance to the study is not always easy to establish: recurrent content (warnings, general information), technical content (menus, cross-references, segmentation of the page), external content (advertisements, links) sometimes connected to the true content and sometimes not, comments and responses of the author to comments, etc. From the data acquisition phase onward, it is therefore necessary to make choices about which information to keep and which to discard.
Figure 1: Exemple of raw HTML page before selection of information
|
<span lang="FR" style="background:white">Auschwitz</span></span></a><span style="color:#000080;"><span lang="FR"><span style="background:white">.</span></span><span lang="FR"> L'album a été classé en 2012 à la 2<sup>e</sup> place du classement des 50 BD essentielles établi par le magazine <i>Lire</i></span></span></span></span></span></p></div><div class="ob-section ob-section-link"><div class="ob-ctn ob-ctn--withImage"><a href="https://www.kizoa.it/Movie-Maker/d92418675kP302368765o1l1/la-shoa-et-la-bande-dessin%C3%A9e-maus" class="ob-link ob-pull-left ob-media-left" target="_blank"><img src="http://resize.over-blog.com/170x170-ct.jpg?http://www.kizoa.com/ajax/cropServlet.php?id=2303079166&kc=9655512&w=480&h=270" class="ob-media ob-img" alt="Movie Maker: La Shoa et la bande dessinée Maus" /></a><p class="ob-title"><a href="https://www.kizoa.it/Movie-Maker/d92418675kP302368765o1l1/la-shoa-et-la-bande-dessin%C3%A9e-maus" class="ob-link" target="_blank">Movie Maker: La Shoa et la bande dessinée Maus</a></p><p class="ob-snippet">Questa funzionalità non è stata attivata dalla persona che ha fatto questa creazione. Puoi richiedere l'attivazione inviandole un messaggio personalizzato. Questa funzionalità è disponibile ...</p><p class="ob-url"><a class="ob-link" href="https://www.kizoa.it/Movie-Maker/d92418675kP302368765o1l1/la-shoa-et-la-bande-dessin%C3%A9e-maus" target="_blank">https://www.kizoa.it/Movie-Maker/d92418675kP302368765o1l1/la-shoa-et-la-bande-dessin%C3%A9e-maus</a></p></div></div> |
{kind=link}
23Once the blogs are selected and their content in HTML, CSS, JS (or any other) format retrieved by a Python script, we get a set of textual information for each article, and only part of that information is relevant to our study. In figure 1, we see a short excerpt from an article retrieved in this way. This illustrates our dilemma: a part must obviously be discarded (e. g. HTML tags), a part must clearly be kept (e.g. the last line, text content displayed as it is on the screen) and a part is subject to a choice (title, replacement text for a missing image or displayed while hovering over an element...).
24We decided on a rather restrictive set of rules to select meaningful data: discard all meta-data (including titles when they are not explicitly displayed), and discard whenever possible repeated text, external content, and comments. This aims at reducing the blog to its minimal content, such as could be found in a press release. Some of the actual content is lost, and we reduce our ability to reproduce a human reader’s experience (which was already impaired by our inability to filter and use images and videos). However, this allows us to homogenize the corpus, limit the impact of redundancy on the quantitative analysis, and ensure that the extracted content of an article does indeed convey its author’s intention and vocabulary.
25Once these rules implemented via new scripts, we finally obtain a total of 39,982 unstructured texts (which we will consider later as simple 'bags of words') for a total of 18,113,739 words or 103,852, 324 characters4.
26Finally, the texts are processed through a series of additional scripts (those are not described here since it would require the reader to get into a huge amount of purely technical details) to deal with encoding, hyphenation, punctuation, capitalization, etc. We do not carry out any lemmatization in this study since it is not at all certain that equating different forms of a word (e. g. singular and plural) facilitates the work of a topic model algorithm. The different forms of a single word may indeed have several distinct uses and therefore possibly different appearance rates, which we may want to detect.
Quantitative methods employed
General Overview
27In this paper, we will successively use the following quantitative techniques:
-
First of all we use topic models to generate lexical fields that we hope are relevant to understanding the corpus, in an unsupervised way. As this process is still relatively uncommon, it is detailed in the next section.
-
We then analyze these topics qualitatively and group them into categories according to our own target interests. We choose to dismiss categories that would lead to a single blog: such a blog is likely to be too unusual or off-topic (e.g. the blog about Japan as detailed later on). This improves the factorial analysis. If we had kept all our categories, we would have had a very discriminant but irrelevant axis such as “Japan”.
-
Finally, with the same tools, we cross-reference these internal data with external, qualitative information, such as geographical origin, gender, age of the author, etc.
28The generation of topics by LDA
29The principle of generating topics by Latent Dirichlet Allocation was first introduced by Blei, Ng et Jordan in 2003 (Blei and al 2003). It is based on the following hypothesis, which serves as the basis for a Bayesian probabilistic model:
-
prior to the writing of articles, there exists some topics, which are basically sets of words, possibly weighted. These topics are not random but have some coherence, we may think of them as lexical fields
-
the observed articles are randomly generated by picking according to various coefficients among these pre-existing topics according to various probabilities.
-
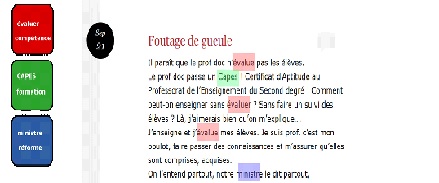
For example, a school librarian’s blog post5 (see figure 2 below) could be obtained by drawing 50% of the terms from a topic called ‘evaluation of students’ (which would contain the terms ‘evaluate’, ‘skills’, etc.), 30% from a topic called ‘teacher training’ (‘CAPES’, ‘training’...) and 20% from a topic called ‘institutions’ (‘minister’, ‘reform’...).
Figure 2: extract from a documentalist teacher's blog
-
 More precisely, the process works as follows. Let k topics T1, T2 … Tk. They are fixed in advance and unknown to us (they are the ‘hidden variables’, in opposition to the ‘visible variables’ which are the article themselves). They represent the mental universe of the teachers and our goal is to discover them. For every articlea:
More precisely, the process works as follows. Let k topics T1, T2 … Tk. They are fixed in advance and unknown to us (they are the ‘hidden variables’, in opposition to the ‘visible variables’ which are the article themselves). They represent the mental universe of the teachers and our goal is to discover them. For every articlea:
-
We pick at random a weighted distribution θ(a) = (θ1, θ2, ..., θk) which sums up to 1. This represents the respective contributions of every topic to article a. Many of these coefficients may be equal to zero, since usually an article is built out of a limited number of topics.
-
For every placeholder p that we want to fill with a word w(p), we pick a topic θi randomly according to distribution θ, which means ∀i, ∀w(p), Pr(w(p) є Ti) = θi
-
Finally we pick at random the word w(p) itself among the selected topic Ti and go back to step 2 for the next word.
30In practice, our articles are the observed variables, while topics and their distributions are the hidden variables we want to compute. Reversing the generative process described above will allow us to infer those variables. This means we have to compute Pr(T, θ/w) = Pr(T,θ)/Pr(w): topics are represented as word distributions, and articles as topic distributions, according to the distribution of observable words. As a 'brute force' approach would be computationally expensive, we proceed to an approximation of these distributions by inference.
31 A large number of algorithms have been proposed to compute such an approximation; we settled for the original Mean Field variational method suggested by Blei and al, mentioned above.
Results
From topics to Categories
32The choice of the number of topics is made prior to running the algorithm. A small number of topics would artificially agglomerate different lexical fields and poorly discriminate information. On the other hand a large number might generate too many lexical fields and less meaningful results. Remembering also that the algorithm only allows a given article to be picked up among a limited number of topics, this number has direct consequences on how the algorithm works. There is no general rule a priori about the ideal number of topics, for it is dependent on the structure of the data (the hidden variables), which by definition we do not know. A systematic cross-validation method would have been too consuming with regard to the size of the corpus. With forty thousand documents, we settled after a few successive trials and errors for 100 topics. This choice was not based on optimization of complexity but on a more qualitative appreciation on the coherence of the topics. However, the results were quite detailed with some topics being very similar to each other. That led us to some post-treatment.
33The qualitative post treatment was made using the 30 more frequent words in each topic. Considering those words, we appreciated what the topic was about. We discarded a posteriori the topics which had little relevance to our study. We eventually grouped the others into large families, which we have called categories, to facilitate the analysis. More precisely, once the 100 topics were obtained, we manually aggregated them into about twenty categories which seemed to have a strong internal coherence, using the same keywords6. Below is presented the list of selected categories (their names are also a choice on our part, already constituting a part of our analysis) with examples of words among the most represented in each category.
34Categories structure our analysis. For example, we have created a "history and web" category for topics that systematically grouped together some words referring to digital objects (e.g. ‘wikipedia’) with words from the history course (e.g. ‘peace’, ‘Rosa Luxembourg’, ‘history’...). We could have chosen to group the topics presenting these characteristics with the category ‘history’ or the category ‘digital technologies’. However, given their massive volume (6 topics) and our a priori interest in digital technologies, we created a specific category for these topics. On the other hand, some categories were merged, such as ‘arts’ and ‘comics’, as they were found to be highly correlated, belonged to the same blogs and constituted a single lexical field.
35Table 1: Presentation of some Categories
|
Category |
Number of topics |
Examples of words (in the original language they were written in) that are frequently represented in topics of this category |
|
Teaching |
13 |
élèves école temps réunion brevet travail notes compétences exemple capacités |
|
Economics |
2 |
région livre croissance économie questions riches Rhône américain travail wordpress |
|
History |
15 |
guerre auteur soldat révolution femmes château travail mondialisation tziganes camp |
|
History and web |
6 |
histoire paris wikipedia libération inrap archives Rosa Luxembourg twitter paix train |
|
Philosophy and politics |
8 |
Alain philosophie liberté adversaire Kant thèse homme Schopenhauer guerre Peillon resistance Chatel mémoire progressistes train politique |
|
French |
6 |
littérature prof inconnu pain opinion lecture avis tome martin poème vérité lire roman |
|
Arts (including Comics) |
3 |
Bauhaus site esprit arts musée histoire Oise fabrique mémoire Compiègne théâtre Thorgal euros série largo années manga histoire orgueil winch séries bibliothèque |
|
Maths |
3 |
triangle maths cours puzzle site monde rectangle problèmes mathématiques |
|
Spanish |
3 |
espagnol Séville ressources flamenco professeur tapas prépositions orientation |
|
Digital technologies |
13 |
numérique session linux jeux enfants élèves émission créer vidéo youtube concours |
|
Clothes |
1 |
prof chaussure vestimentaire lycée monde genre style blanche stéréotypes vêtements |
|
Media and terrorism |
6 |
liberté news pensée privée fake expression vacances prison paris caricaturistes livre |
|
Travel |
6 |
pays découvrir hôtel Reims Bologne écriture temps voyage place ville parle Séville |
|
Leisure |
3 |
cinema paris quartier voyage journée café temps passe plaisir films positive découvrir |
36The set does not sum to 100 because the remaining 9 topics do not exhibit any internal consistency; it is common to have about 10% unusable topics of this type with this algorithm (cf Blei and al. 2003 or Teh and al. 2005) Indeed, although all words are classified (except those that are eliminated a priori like articles or prepositions for example), some carry little meaning, and the algorithm might indiscriminately distribute or aggregate them. At this stage, we also decided to remove some categories such as "Japan" which represents less than 3 blogs or "Movies" which we decided was not relevant to a first analysis. It is also at this stage that the last regroupings and readjustments are carried out.
37It is noteworthy that many of these categories are straightforward disciplines. Disciplinary lexical fields are expected: the majority of professors (but not all) write about their teaching practice, and furthermore write much more about their own discipline than about other disciplines. Such a discriminating field is therefore likely to be well identified by the algorithm. The exceptions (fields that are not disciplinary) include: the teaching profession in general, leisure, politics or digital technologies.
Distribution of Categories inside the corpus
38 ‘Teaching’ (occupation, classroom management, etc.) is the topic most often discussed by teachers. This represents a median of almost 40% of a blog content, at minimum 2.9% and at most 90.5%. This makes it, regardless of the indicator, the most important subject.
39The disciplinary categories ‘French’ and ‘history’ are related to the predominance of French and history-geography teachers in the selected blogs. The disciplinary lexical fields (Spanish, Economics, French, ...) represents a median of 1% in of the topics, but for some teachers, this rises to 73% in history or 62% in mathematics. This result shows that teachers tend to be concerned about teaching or pedagogy more than the specifics of their discipline. Only discipline-centered blogs have a strong disciplinary lexical field. More generalist bloggers tend to write less about their discipline: they either offer a reflection on their practice or on political issues.
40It is worthy to note that the ‘digital technologies’ category is, along with ‘teaching’, the only one that does not have a minimum of zero7. Digital technologies, much like classroom management, are now part of common class parlance for all teachers writing a blog. Digital technologies represent a median of 6% of the categories covered in our teacher blogs.
41When dealing with categories, it is interesting not to limit oneself to global statistical indicators, but to look at the distribution of the corpus, so as to distinguish between common vocabulary and more discriminating elements. Below can be found the distribution profile of topics by blogs for the four non-disciplinary categories (‘digital technologies’, ‘teacher job’ …):
Figure 3: Distribution of categories according to the frequency of apparition per blog
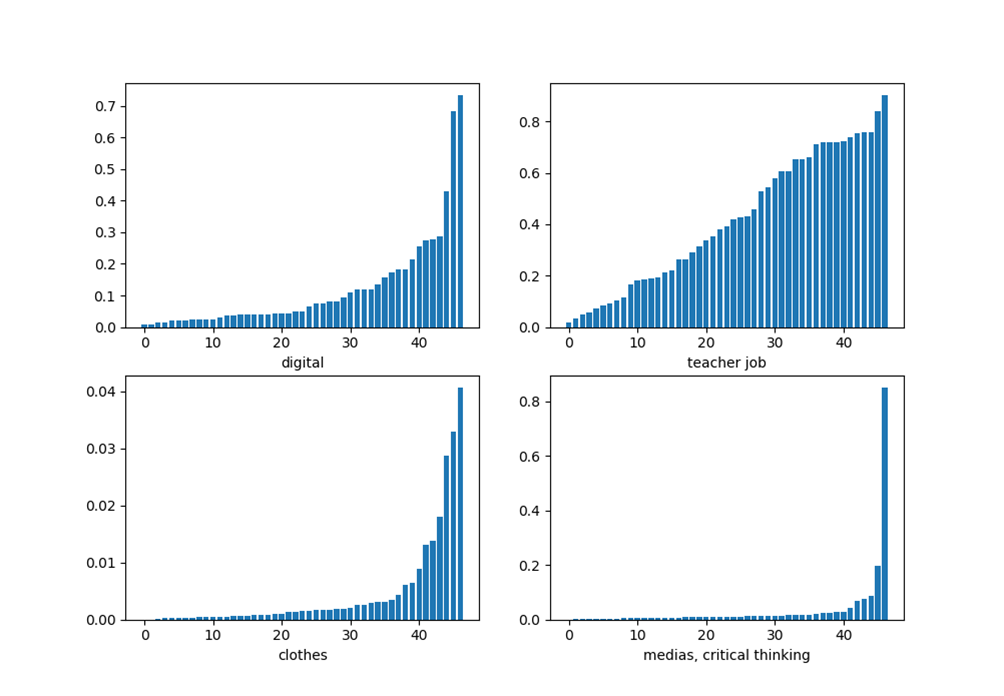
42The y-axis gives the proportion of words in a blog which belongs to the family of topics concerned. Each bar on the x-axis corresponds to a blog, sorted in ascending order of the proportion for ease of reading. Apart from 'clothing', which peaks at 4%, we see that each family contains at least one blog in which they have a large majority. However, the shape of the distribution varies a lot: the 'teaching profession' topic makes up for a significant proportion of three quarters of blogs, while the ‘media’ topic is almost entirely dominant in a single blog. Finally, 'digital technologies' is a topic used in a significant way by a majority of blogs, but constitutes the major topic in a small part of them only. We notice that 'clothing', like 'digital technologies' is an interesting category from the point of view of discrimination as it allows us to distinguish between 6 or 7 blogs which refer to it significantly more than other blogs.
43Disciplinary categories match well to disciplines overall, although the "French" category is also used by other disciplines. The "French" category represents 5% of the topics used by French blogs but less than 2% of the topics used by teachers of mathematics or other technical subjects.
Analysis of Categories
44Apart from the ‘education’ category, only four categories are non-disciplinary: ‘digital technologies’, the category ‘critical thinking, terrorist attack, media’, the subject of ‘clothing’ and all the subjects ‘leisure, travel’, which can be analyzed together as we will do below.
45These subjects do not appear during interviews, even non directive ones: it is the combination of the choice of sources and the method of analysis that allows them to emerge. When we tried basic quantitative analysis on specific terms to check, they did not appear neither (too many ways to express an idea): we really need the topics to observe what is happening.
46Overview
|
Methodological note The Principal Component Analysis presented here uses categories as active variables. We use the frequency of use of a category for the measure of distance (number of times when a given category appears, divided by the number of categories used. The unit is the number of groups of words the category includes). The analysis was performed with R, using the FactominR package, with the default configuration (Euclidian distance, no normalization). The reason why we did not need normalization is that all our variables are percentage and thus already lie between 0 and 1. We have a total explained variance of 26% on the two first axes, compared to 13% if the model did not explain anything (because there are 15 categories8). In other words, analysis explains twice as much variance as randomness. This PCA allows us to observe the combinations of lexical fields (or categories) that most distinguish blogs from each other. We added in red the barycenters of the major teaching disciplines with respect to the categories they cover. As a reminder, the closer a variable is to the correlation circle, the better its projection and interpretation. The only variable, apart from categories, which is added on the graph is "rural_urban" which actually points to teachers in urban areas. Symmetrically, negative numbers refer to teachers in rural areas. The variables "region" or "disciplines" are too numerous to be included in the graph. Nevertheless, some disciplines are shown in red on the graph. |
47No gender differences appear, men and women are roughly at the center of the graph.
Figure 4: PCA on categories
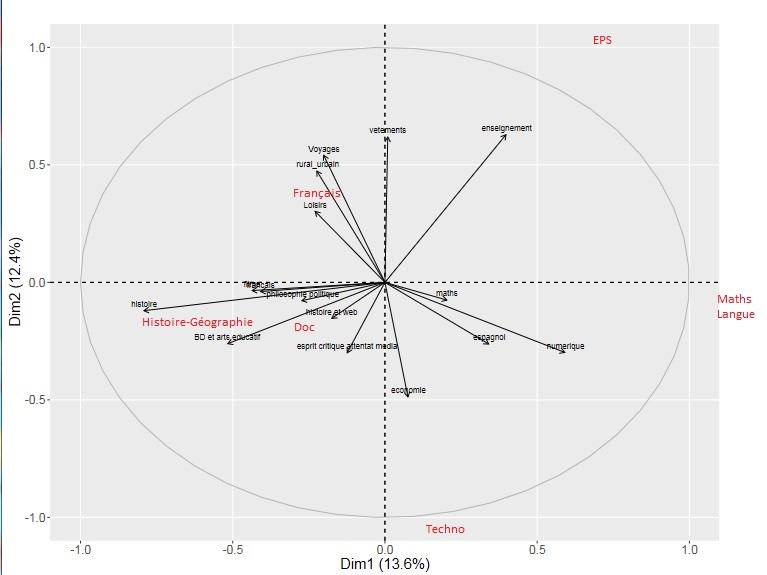
48On figure 4, we note a first axis which discriminates math and language blogs from blogs by history and geography teachers. Among the lexical fields differentiating these blogs, we obviously find the disciplinary categories on both sides but also, quite remarkably, the "digital technology" category (with words such as linux, youtube, session, video...) opposing the "history" category (with words such as history, liberation, France, borders...). However, other words of the digital universe such as "wikipedia" or "creative commons" are found in history, French or documentalist topics. These therefore represent different concerns around the theme “digital”. Some words such as Wikipedia belong to the “digital technology” lexical field for maths teachers, but are considered as a disciplinary topic for history teachers. So we can observe two ways of talking about digital tools depending on the discipline taught, ways that are highly convergent with previous works (Epstein 2017) where we could observe the legitimacy of math teachers (with computer science) and language teachers (with the language labs) to write about digital techniques. It also confirms that some digital tools such as Wikipedia are not related to the digital environment but to some specific disciplines in which documents are studied such as history or documentalist studies.
49The second axis is essentially created by the "dress code" lexical field, which is orthogonal to concerns about digital technology or history. The category of "critical thinking in media attacks", although not very significant and poorly represented on the graph, would be slightly on the opposite side of axis 2.
50Aside from technology teachers (3 blogs), who do not talk about dress code at all, there is no specific disciplinary element separating the other blogs, with the possible exception of the one written by the sports and physical education teacher – we will discuss that point further in the article.
51Unexpected hot topics
52The choice of sources and method brings out three topics that we had not anticipated (apart from the expected digital technology topic and the disciplinary topics). We choose to present two of them: the “terrorist attacks” and the “clothing” categories because they probably would not have been observed without the kind of inductive analysis we have proposed.
53Category: critical thinking, terror attacks, media
54That category groups 6 different topics:
55Table 2 : Presentation of the topics in the « Critical thinking » Category
|
General Idea |
Keywords |
|
Caricatures, media drawings |
Charlie Hebdo, dessinateurs, condamne, presse, Facebook, caricaturistes, journal, procès, harcèlement |
|
Critical Thinking |
Pensée, recherche, créative, éducation, communauté, élèves, vigilante, enfant, réflexion, raisonnable, monde, école |
|
Digital information and Democracy |
Fake news, click, éducation, écoles prioritaires, démocratie, digital |
|
Power struggle and freedom on the internet |
Liberté, privée, Snowden, sécurité, état, protéger, pouvoir, gouvernement, cacher, société, citoyens, surveillance |
|
Public speech |
Liberté, expression, responsabilité, société, pensée, limites opinions publiques, violence, presse, medias, droit, France, vrai, débat |
|
Terror attacks in Paris |
Paris, élèves, photos, attentats, réseaux sociaux, avenir |
56The fact that these topics are predominant for history-geography teachers and documentalist teachers confirms their role in media education. Indeed, while the entire teaching force is supposed to take up media, digital technologies and citizenship education, the specific roles of each teacher are actually well specified9. For instance, an official report following the attacks of November 2015 states that "the training of the individual and the citizen is the task of all disciplines and of moral and civic education" - the latter being attributed to history and geography teachers. Likewise, this report puts an emphasis on the role of a documentalist teacher: "media and information education must question democratic issues related to journalistic information and social networks". These blogs’ posts also attest to the need for discussion among teachers on these subjects. Indeed, just after the attacks at Charlie Hebdo, middle school teachers had to propose, with minimal or no training, pedagogic sequences outside of their fields of competence (particularly for history and geography teachers who are already in charge of civic education). Many of them tried to think collectively or publicly about such sequences from the different angles of approach proposed above, i.e. press drawing and cartoons, online information, critical thinking, etc., in order to make them accessible to the general public. We can see the “democracy effect” described by Cardon (2010) as a horizontal approach to a problem that teachers tried to solve collectively. Interestingly enough, the topics do not contain the words "sources" or "conspiracies" among the most important. It is likely that either the work on sources (which had already been in the official program for quite a while) did not raise any particular questions or that it ended up in the more general lexical fields of historical-geographic literature review, and additionally that there was no particular "conspiracy theory" about these attacks - at least initially - or that it was no concern to the teachers.10.
57Even if such themes are specific and have not been classified as "digital technologies", we note that the digital aspects (Facebook, fake news, surveillance, Snowden...) are very present in these subjects and that ‘information’ is well understood as ‘online information’.
58Clothing, clothes and dress code
59This lexical field has an important weight in the creation of the second axis.
60The use of the lexical fields of "Clothing" covers several realities. It first includes the concerns of one physical education teacher, who mentions difficulties with students coming in class without proper gym clothes. Second, teachers (PE and others) have questions about their own outfits, even if the PE teacher faces the specific issue of locker rooms (for him/her as well as for the students) and of where to change clothes. Although this is not something that all teachers talk about, a majority of blogs have used this lexical field at one time or another. For most of the teachers we read, this is often a humorous blog post (or part of such a post) covering questions such as "can I wear my sneakers in class?" or "Do I need to wear a suit to look more serious?”. According to our (non-exhaustive) observations, the clothing and dress code issue in blogs mainly concerns teachers rather than pupils11. Even if the question is often framed in a derisive way and the study is "only" on 47 blogs12, the emergence of this topic in 45 of the blogs must be questioned and understood as a concern that may not be major but does exist among teachers.
61As a subject which is neither central nor technical, it is therefore not considered a legitimate topic for discussion among colleagues. In addition, there are no official instructions on dress code. More specifically, it is stipulated that students must wear "proper clothes" without specifying what “proper clothes” are, with the exception of religious attributes. Some schools’ internal rules specify the notion of what is "appropriate" for teachers and students, but generally speaking this is left to individual appreciation. On anonymous blogs, teacher-authors raise the subject more freely. There are two elements observed on the digital front: 1) the question of the institution's place in the validity and legitimacy of such an interrogation and 2) the Internet as a place for discussion, in particular blogs as a space for expression. Thus, the issue of pupils' clothing and dress code (for example, wearing a veil, which does not appear at all in the blogs studied) is assumed to be a legitimate topic for discussion, but the teachers' dress code is left to informal and non-explicit norms. Alongside Marcus O' Donnell (2006) who states that the blog is one of the elements of teachers' cyberculture, the blog is also, for teachers, a place to raise questions having no institutional legitimacy. It is particularly interesting to see the emergence of the web as a space for sociological revelations. In fact, in quantitative questionnaires or interviews, including non-directive ones, no teacher ever mentioned any dress code problems, although they appear here. In response to this analysis, some teachers confirmed that they did sometimes ask themselves such questions, or other times had remarks from their pupils. Teachers would wonder whether they might appear too "cool" or too "lax" or on the contrary too distanced from the students by adhering to a different dress code. As the example of some teachers who hesitate between promoting a legitimate culture (Bourdieu 1979, 1998) versus taking the pupils' culture as a starting point during their classes suggests, the dress code issue becomes a pedagogical one and a question of positioning oneself in the class as a model and potentially modeling adult.
62It should be noted that there is no difference between men and women in the use of this lexical field. On the other hand, in the Student test, it is significant (p<0.01) to note that this is more of concern for urban teachers than rural ones.
Conclusion
63We started with some limited knowledge of the corpus (such as who wrote the article, when, and possibly contextual data about that person’s life) and some a priori questions. These questions were connected to our research interests, mostly how digital technology concerns are expressed and what that implies for teachers. However, we decided not to take into account that knowledge and problem in the first part of the study, and instead we let the topic model algorithm run unsupervised and lead us to a self-categorization of the data. The results allow us to discover fields of interest we had no prior idea about, and which would have gone totally unnoticed with either a supervised method (like direct research of expressions) or a qualitative one (of a necessarily limited number of articles, where the fields in question would not have appeared). The method also seems to strengthen our initial assumptions that there is a gap between perception and practice of digital technologies. Perception is almost only institutional while practice is much more diverse and usually decorrelated from perception – but that is now a lead for our upcoming research.
64Such emerging topics include the interest of teachers in non-institutional, non-disciplinary fields, having thus a lower level of respectability, such as clothes (dress code) or hobbies (travels, comics, etc). They also include widespread concerns about the profession that fail to find institutional answers, such as questions about terrorist attacks, the role of the media and critical speech. These topics, in the same way as the use of digital technologies, find a support in the blogs that they would not find elsewhere. The choice of the blog as material for this study, combined with the choice of our inductive method mixing qualitative and quantitative exploration, have specifically allowed us to uncover this.
65While this study covered only 47 blogs, it corresponds to 40,000 articles. Thus we are well beyond what a strictly qualitative study would have allowed us to achieve. We find ourselves in the situation where quantitative analysis allows us to explore larger volumes of data and to develop exploratory leads. This would never have been possible had we been restricted to a more limited corpus.
66However, there are several limits in this study and we need to recall them in order to consider what will be interesting as future research.
67First, there are some strong hypotheses in the choice of topics model as a basis for lexicometry that may be challenged or refined. We already discussed the fact that it is a stochastic process and we do not believe that is a problem per se, since there is a long history of random algorithms being used for very good approximation of human behavior (Englebienne 2011). On the other hand, this specific algorithm does not take into account any a priori external information related to the blog the article belongs to, its author, or even the date of the article. However, the topic model algorithm itself leads to a segmentation a posteriori of the blogs. Some of them are mostly disciplinary, some of them are focused on subjects with a very specific timeline (such as ‘terrorist attacks’), etc. A closer look at this segmentation shows that it correlates with the external information that was not included in the algorithm. That gives us the hint that we might try a different set of hypotheses, where the distribution of probabilities of the topics would be dependent on some additional hidden variables, such as ‘author’, ‘date’, ‘discipline’. We could run the algorithm and see if the predictions for these variables are coherent with what we already know about the real values.
68Second comes the limitation of the material itself. While we have been discussing extensively the specific interests of the blog, we must also consider that it would be interesting to compare the results with those stemming from other material that have different virtues. For instance, we plan to run similar quantitative studies on Twitter material. Tweets, as they are short and often respond to each other, are not as rich as blogs and do not always deal with the same topics; however they allow us to study a much bigger sample of teachers, and certainly emphasize community dynamics. At the opposite end of the spectrum, we will triangulate conclusions from our study with more qualitative results issued from interviews or direct observation.

Bibliography
BLEI, D., NG, A., & JORDAN, M. (2003). Latent Dirichlet Analysis. Journal of Machine Learning Research, 3, 993–1022.
BOURDIEU, P. (1979) La distinction, Paris: Éditions de Minuit.
BOURDIEU, P (1998) La Domination masculine, Paris: Seuil.
LAVENIR, G. & BOURGEOIS, N. (2017) “Old people, video games and french press: a topic model approach on a study about discipline, entertainment and self-improvement..” MedieKultur: Journal of media and communication research, Sara Mosberg Iversen, 2017 .
CARDON D., et DELAUNEY-TETEREL H., (2006) « La production de soi comme technique relationnelle », Réseaux, n°138, pp. 15-71.
CARDON D. (2010) La démocratie Internet. Promesses et limites. Paris: Seuil.
DARDY C. (2016) « De quelques usages sociologiques des récits en édition numérique » in Sociologie et sociétés, Volume 48, numéro 2, automne 2016, p. 261-283
ENGLEBIENNE G. (2011) Bayesian Methods for the Analysis of Human Behaviour. In: Salah A., Gevers T. (eds) Computer Analysis of Human Behavior. Springer, London
EPSTEIN M., BOUCCARA S. (2015) Evolution des pratiques enseignantes et des positionnements des professeurs à l’heure du numérique – Colloque Condition(s) enseignante(s) – Lyon 2015
EPSTEIN M, (2016) Etude clinique d’un projet de prévention du décrochage scolaire avec des outils numériques dans des collèges publics franciliens par une association composée de collaborateurs d’entreprises et d’enseignants. – Colloque Nouvelles Problématiques Educatives - UPEC, Créteil 2016.
EPSTEIN M. (2017). Outil transdisciplinaire et interdisciplinarité entre enseignants- Cas du numérique au collège in L’année de la recherche en sciences de l’Éducation 2017. p121-138
GOFFMAN E., 1973 (1959), La mise en scène de la vie quotidienne: la présentation de soi, Paris, Éditions de Minuit.
HENAFF N. (2009), « Étude d'un blog pédagogique. Le blog d'une enseignante en histoire-géographie», Distances et savoirs 3/2009 (Vol. 7) , p. 377-398
URL: www.cairn.info/revue-distances-et-savoirs-2009-3-page-377.htm.
JONES, M and ALONY, I, (2008) Blogs - the new source of data analysis, Journal of Issues in Informing Science and Information Technology, 5, 2008, 433-446. Copyright The Informing Science Institute 2008.
LADAGE, C. & RAVENSTEIN, J. (2013). Internet et enseignants: entre contrastes et clivages. Enquête auprès d’enseignants du secondaire. Sciences et Technologies de l’Information et de la Communication pour l’Éducation et la Formation (STICEF). Vol. 20.
LANG ME (2016) Le blogue « privé » comme méthode de recherche en études féministes in Recherches féministes, Volume 29, numéro 1, 2016, p. 71-90
MATALON B., GHIGLIONE R. (1998) Les enquêtes sociologiques. Théories et pratiques. - Paris: Armand Colin.
MORTENSEN T., WALKER J., (2002) « Blogging thoughts: personnal publication as an online research tool », http://mrkim.2myclass.com/kkim/uofcmed/677major/module6/blogging_thoughts.pdf
ROUQUETTE S. (2008), « Les blogs « extimes »: analyse sociologique de l’interactivité des blogs », tic&société [En ligne], Vol. 2, n° 1 | 2008, mis en ligne le 13 octobre 2008, consulté le 13 novembre 2016. URL: http://ticetsociete.revues.org/412; DOI: 10.4000/ticetsociete.412
http://www.odw.fr/etude-relations-blogueurs
TEH YW, JORDAN MI, BEAL MJ, BLEI DM (2005), “Sharing clusters among related groups: Hierarchical Dirichlet processes”. In L. Saul, Y. Weiss, and L. Bottou (Eds.), Advances in Neural Information Processing Systems (NIPS) 17, 2005
Notes
1 In French, adjectives and past participle agree with gender and plural of the subject in most circumstances
2 During their first year as teachers, primary, middle and high school professors used to attend extra theoretical and practical lessons at an institute then called “Institut de Formation des Maîtres” (IUFM) which became EPSE so that it gives an idea of seniority.
3 This figure comes from a yearly statistical report named « Repères et références Statistiques » which is issued by a state organism called « Direction de l’Evaluation, de la Prospective et de la Performance » http://cache.media.education.gouv.fr/file/2017/41/4/depp-RERS-2017-personnels_824414.pdf
5 In France, a school librarian is a full teacher, who has the same diploma as any other teacher. We will call them documentalist teacher to be closer to this reality
6 we tried groupings using traditional quantitative grouping techniques (such as Agglomerative Hierarchical Clustering) but the results were not really interpretable and less relevant than the manual classification even if it was partially concordant.
7 Zéro are « real ones » meaning there is no such topics in the concerned blogs
8 1/15 (categories) *2 (axes)=13%
9 Le bulletin officiel n°11 du 26 novembre 2015 http://www.education.gouv.fr/pid285/bulletin_officiel.html?cid_bo=94717
10 The word « conspiracy » does not appear at all in the studied blogs (or a too little amount of time to be part of the 10000 studied words)
11 The method used does not statistically verify that this is a significant phenomenon. This should therefore be seen as a qualitative analysis.
12 As a reminder, we consider from experience that we arrive qualitatively at "saturation", that is to say that we saturated the contribution of information emerging from a new interview at the end of about fifteen interviews and for a quantitative study, we consider that we reach the law of large numbers for n=50. To put it another way, in our case, it is certain that the concern exists reading the teachers' blogs (qualitatively) without being certain that it is representative quantitatively.
To quote this document

Ce(tte) uvre est mise à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International.